アイデアと手腕で入賞を狙う~データ分析コンペ体験記~
目次[非表示]
- 1.はじめに
- 2.データ分析コンペの紹介
- 3.コンペの参加テーマと分析アプローチ
- 4.審査の採点基準と作戦
- 5.分析チームへの参加動機
- 6.私たちの分析チームの方針
- 7.考え抜く努力と手段
- 8.チームの中間状況
- 9.おわりに
はじめに
パートナーブログをお読みいただいている皆様、はじめまして。ネットワンパートナーズ株式会社(以下、当社またはNOPという)の若手SEが、日々の技術業務の中でどのように過ごしているかの一端を紹介する “Challenge Blog” 記事の第4弾です。
前回までは入社2年目のメンバーが担当していましたが、今回からは1年目のメンバーである筆者が書くことになりました。今回、筆者は先輩に誘われて、 ネットワングループ(以下、当社グループという)で開催されている「データ分析コンペ」に参加する機会を得ました。私がデータ分析コンペに参加することになった理由、データ分析をしていて苦労したこと、実際にデータ分析を手掛けて初めて理解できたことを、入社1年目の目線でまとめてみました。
データ分析コンペの紹介
ここで、データ分析コンペについて紹介します。これは、2019年から開催されていて、今回は記念すべき第10回目の開催です。開催の目的として次の3点が掲げられており、これらを達成するために様々な方法でデータ分析を行う機会が提供されています。
- データ分析を競いながら楽しく取り組むことで “データを扱える人材” の育成を目指す
- 社内の課題や実データを用いて分析することで、ネットワンDXへ貢献する
- 分析することで社内の課題を全社員が自分ごととして捉えられるように促す
過去のテーマには、従業員の年齢、性別、勤続年数及び昨年の昇給率などの個人データを入力し、その人の職場と仕事の満足度を予測するモデルを制作したもの、あるいは社内の技術資料をテキストマイニングで分析することで、複数の技術要素が混在していて求めている情報になかなかたどり着けない状況を改善するもの、などがありました。
コンペの参加テーマと分析アプローチ
今回、私たちが取り組むテーマは、「役務品質を上げ、“自責トラブルをゼロにする“ にはどうすればよいか」です。分析対象として提供されるデータは、当社グループの業務におけるトラブル事例であり、次の項目から構成しています。
例)事象内容・要因・根本原因・対象製品、トラブル発覚日、対応日、自責トラブルか他責トラブルか、アカウント会社名 等
私たちの活動ですが、おおよそ次のようなものです。まず、「特定の製品でトラブルが多く発生しているのではないか」などの仮説を立て、それをデータ分析で立証します。「○○社の製品でトラブルが多い」「特に○○というミスが頻出している」などの傾向から、どうすれば自責トラブルをゼロにできるのか、対策案を導き出します。その対策を発表会で提案する、というのが大まかな分析アプローチです。
審査の採点基準と作戦
データ分析コンペの審査の採点基準は3点です。
- 分析能力・論理性
- 創意工夫・着眼点の良さ・発想の面白さ
- 業務への貢献性・現実性
今回(第10回)のテーマは、すでに第6回で取り上げられたことのあるテーマなので、第6回の入賞作品とは異なる視点で分析する必要があります。その入賞作品を紹介すると、トラブル事例を対象製品ごとに分類し、トラブル数の多いTOP3の製品について集中的に分析を行うものでした。具体的には、根本原因の文章データのテキストマイニングです。そこで導かれた結論は、次の二つでした。
- 製品群Aのトラブル事象では、特に体制・コミュニケーション不足という言葉が頻出していることが分かったので、この製品については管理体制の強化、レビューの実施などの対応策が有効である。
- 製品群Bについては、特に知識経験不足に関連する言葉が頻出しているので、人材育成と有識者とのナレッジ共有の場を設ける等の対応策が有効である。
このほかの入賞作品の分析アプローチも合わせて見ると、容易に思い付く方法はすでにやり尽くされていて、入賞を狙うには、特色あるアイデアの考案が肝になることは間違いありません。
分析チームへの参加動機
さて、ここで筆者自身のことを書きたいと思います。筆者がこのデータ分析コンペに参加したのは、データ分析のための比較的新しい技術に触れることで、現在開発されているサービスや、お客様の事業についてより深く理解できると考えたからです。そもそも、このような考えを持ったのは、次のエピソードがあったからです。
筆者が入社・配属直後の2024年6月、部門研修(新卒OJT)の中で、Interop Tokyo 2024 (以下、Interopという;写真1はその様子)を見学する機会がありました。Interopは1994年から開催されている、歴史あるインターネットテクノロジーのイベントであることは周知のとおりですが、昨年は注力テーマとしてAIインフラ/データセンター・生成AI /AI Opsなどが選ばれており、今後さらにAI等の最新技術の利活用が進んでいくことを予感させました。

写真1 Interop Tokyo 2024の様子
しかし当時の筆者としては、Interopで展示されていた、AIやデータ分析のためのインフラストラクチャや、データを整形するソフトウェアなどの重要性が理解できず、「よく分からないが必要なのだろう」という程度の認識に留まっていました。それでも、これらが今後のネットワーク業界に大きな影響を及ぼす最新技術であることは分かっていたため、技術の内容、実装、そこから導かれる新世界が理解できないことに不安を感じていました。
そんな中、当社グループでデータ分析コンペが開催されていると知り、自らその場に飛び込んでみるのが理解するには一番早いと考え、まずはデータ分析コンペの体験会に参加することにしました。参加してすぐに、データを整形するソフトウェア(ツール)が必要な理由が分かりました。たとえば今回のデータ分析コンペで主催者側から提供されるトラブル事例のデータでは、トラブルが発生した日とクローズ日(解決した日)が記録されています。問題の解決にかかった日数は二つの値の差になりますが、実際に試算してみると0以下だったり600以上だったりするものがあり、明らかに誤データが一定数混在しています。数値では、あり得ない値の判別が容易で、データの数も条件の絞り込みによって600~800程度になるので、誤データを除外することは手作業でも可能でしょう。しかし、数万の文章データの中から誤データを探し出すのは、非常に困難だと感じました。こうしてデータ分析を少しかじるだけでも多くのことが学べたと感じているときに、同じくデータ分析コンペ体験会に参加していた自部門(セールスエンジニアリング部)のK先輩に、「本番のデータ分析コンペに一緒に出てみないか」とお誘いいただきました。これは専用インフラストラクチャについて理解を一層深める良い機会だと思い、二つ返事で参加を決めました。
私たちの分析チームの方針
私たちの分析チームは、K先輩をリーダーに、同期のY君と筆者の3名です。プロジェクト活動のキックオフでは、K先輩にデータ分析を進めていく流れを決めていただき、次の順序で進めていくことになりました。
- とにかくたくさんの仮説案を出す(なるべく先を見据えて面白そうなもの)
- 三つの評価基準を軸に各案を評価していき、最大2案まで絞る
- 分析して、面白い案1本に絞る
- 分析結果の資料化
- 発表資料を課題の具体例や活用案できれいに(色付け)していく
筆者の業務(本業)は、お客様からの技術QA対応であり、隙間時間を捻出してプロジェクトを進めていかなければなりません。それでも、日頃がむしゃらに集中して時間をかけて仕事を終わらせている筆者の目には、目的の決定とスケジュールに従った進行というエレガントなプロジェクトのスタイルがとても新鮮に映りました。
考え抜く努力と手段
先の進め方の順序に従い、まず仮説案を3人で合わせて10個ほど作成しました。前にも述べましたが、過去に一度実施されたテーマということで、過去の入賞者と違う視点を設定する必要があります。簡単に考え付くものは、前回に誰かがすでに発案済みなので、そう簡単に思い付くものではありません。中間報告では仮説案出しのノルマの三つのうち二つしか出せず、K先輩にはもう少し案を持ってきてほしいと言われてしまいました。そう言われても一人で考えていたのでは同じような案しか思いつかず、データ分析に必要とされる、「課題の背景を理解して、ビジネス上の課題を整理し、解決に導く」ためのスキルが不足しているのを痛感しました。同期のY君はどうだろうかと聞いてみると、同じ悩みを抱えていることが分かりました。そこで、アイデア出しには対面でブレインストーミングを行おうと、当社のオフィスであるイノベーションセンター (呼称:netone valley )にて話し合いを重ね、二人で新たに三つの案をまとめることができました。案の絞り込みの会議では、大会の評価基準に合致し、かつこれまでにない視点であるという条件を満たしていることで、筆者とY君で考えた案が採用されることになりました。
チームの中間状況
私たちのチームは、進め方の順序の1・2項の段階を経て、絞った二つの仮説案を基にデータ分析を行っています。ここで使用している分析ツールは “Altair AI Studio”(図1は操作画面) と “KH Coder” です。前者は主にデータの整形及び可視化に、後者はテキストマイニングで文章データの特徴の把握に、それぞれ使用しています。
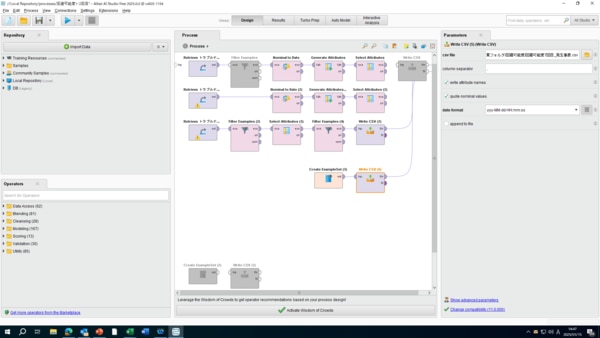
図1 Altair AI Studio の操作画面
データ分析コンペ体験会ではテキストマイニングを使用していませんでしたし、ましてや KH Coderを使用するのは今回が初めてなので、慣れていないことばかりです。仮説案出しに続き、データ分析でも苦戦しています。それでも実際にやっているうちに、 KH Coderの機能としてデータの整形が組み込まれているので、形式を比較的容易に整えることができました。もし、このような分析ツールがリリースされる前、またはセキュリティなどの観点から使用できない場合には、Pythonなどのプログラミング言語でコーディングしたり、Excelで一から処理のための式を書くことになるので、筆者のようなド素人にとっては無理難題と言わざるを得ません。続く3~5項についても、先人の努力と成果に感謝しながら、プロジェクトを進めていきたいと思います。
おわりに
筆者は、今回のデータ分析コンペに参加し、具体的にはデータ分析のツールや専用のインフラストラクチャに触れることができました。今後、生成AIやデータ分析の領域は、ますます存在感を増していくと考えられます。Cisco Systems社が、2024年にAIソリューションの拡大・開発を目的とした10億ドルのグローバル投資ファンドを設立したことからも、それが伺えます。
その中にあって、当社グループは変わらず価値を提供し続けるために、筆者は一個人としても常に最新技術へのアンテナを張り、日々の業務に活かしていきたいですし、案件をいただいているお客様(パートナー様)とその先のエンドユーザー様の事業へ貢献していきたいと考えております。最後までお読みいただきありがとうございました。
■関連記事