

統合データ保護基盤 Druva inSync/Phoenixについてご紹介
こんにちは!
Druvaの製品担当、川口です。
今回はクラウド型(SaaS)統合データ保護(バックアップ)基盤であるDurva inSync/Phoenixのご紹介をしたいと思います。
目次[非表示]
バックアップとは、そして重要性
このブログを読んでいる皆さんにバックアップとは?いう説明は今更かと思いますが、簡単におさらいさせていただきます。
コンピュータ上に保存されているデータは、内蔵された何らかのメディア上に保存されます。現状ではSSDもしくはHDDのどちらかになるかと思います。HDDよりは壊れにくいとはいえ、SSDも最後は必ず壊れますし、これがたとえばクラウド上に保存され、ハードウェア的な保護がクラウド事業者によって担保されていたとしても、人為的もしくは偶発的な事故によってデータが消去される可能性は残ります。データは必ず消失する、という前提に立つ場合、別の場所にコピーを取得しておき、データが失われた際にはそこから戻す(リストアする)必要があります。これがバックアップ(&リストア)です。
以前はコンピュータに直接接続されたテープメディアに取得することが多かったのですが、近年はバックアップ用のソフトウェアがインストールされた統合バックアップサーバに接続されたハードディスク上に取得される場合がほとんどかと思います。
エンドポイントバックアップ
サーバのバックアップは慎重に検討され、必要十分なバックアップがとられるものですが(もちろん例外も・・・)、エンドポイント~ここでは従業員に支給された個人用の端末のことを想定しますが~についてはそれぞれの使用者の判断に任されることが多いかと思います。VDIなど情報システム部門ですべて管理している場合は別として、現実的には個々のエンドポイントデバイスについてはバックアップを取得せず、必要なデータはファイルサーバ上に置く運用が主流になっています。
しかし往々にしてそれぞれのエンドポイントにもファイルは置かれ、バックアップされていないエンドポイントの機器が万が一破損し、データが回収不可能となった場合、当然それまで作業していた成果物は永遠に失われます。使ってる当人は普段気にしてないですが、いざ壊れるとかなりショックです・・・。
Druvaって何?
USに本社のある会社です。言葉の意味としてはサンスクリット、ヒンドゥー語で北極星ということになります。常にそこにあり、継続的で信頼でき、確固たる地位を持ってお客様のデータを守り続けるという意味が込められています。

Druvaは2008年にヴェリタスソフトウェア(当時はシマンテックでしたが)のエンジニアが中心となってインドで創業されました。
オンプレミスのエンドポイント向けバックアップソリューションから始まり、2010年には追加の出資を受けて本社をシリコンバレーに移し、2012年にはAWSインフラを使ったクラウド型のエンドポイントバックアップソリューションをリリースしました。
2015年に日本法人を設立し、販売を開始しています。
#よく聞かれるのがDruvaってどう読むの?ということなんですが・・・
⇒答え、我々は”ドルーバ”って呼んでますが日本法人の方曰く、好きに読んでください、とのことでした。
Druvaを使うと何ができるのか
Druvaを一言で説明した場合、クラウド型、統合型データ保護基盤ということになります。
エンドポイント(デスクトップ・ノートパソコンからスマートフォン、タブレットなど)からクラウドアプリケーション(Office356やBOXなど)、サーバー(物理サーバ、仮想サーバ)までを、inSyncとPhoenixの二つのラインナップで統合的に保護(バックアップ)します。

また保護するだけではなく、発見検知検索といった機能でデータを有効活用することも可能です。
この2種のソフトウェア/サービスについては次回以降詳細に説明させていただきます。
Druvaの特徴
ここではDruvaの特徴をお話しいたします。
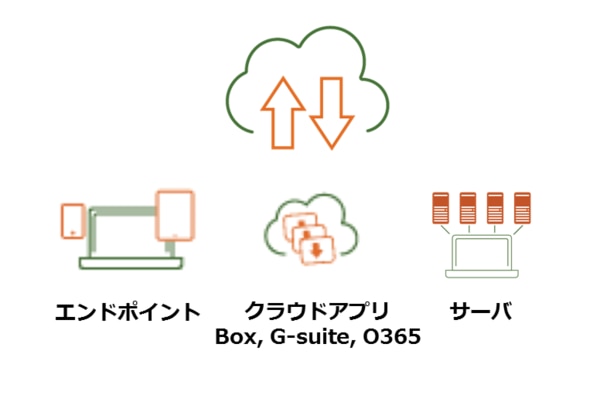
まず一つ目、クラウドネイティブで集中型ということがあります。
Druvaの基盤はクラウド上にありますので、オンプレのバックアップ基盤で必要になる初期のサイジングは不要です。また高い拡張性も同時に兼ね備えています。
さまざまな拠点のデータを保護可能ですが、これは世界中のどこでもというレベルです(当然ネットリーチャブルである必要はあります)。
またバックアップはクラウドで集中管理できますし、これはオンプレで基盤を作ってる場合よくありますが、定期的バージョンアップは不要です。サポートが切れるのでバージョンアップしてくださいと言われて実施するのですが、コンパチ確認やライセンスの移行などがあったりしてそこそこの工数が掛かったりします。

次に効率的で高い費用対効果を持つということが挙げられます。
クラウド基盤上のグローバル重複排除を行うことにより、データを圧縮します。そもそもエンドポイント・サーバからの転送データを最小限に抑えることができバックアップ自体も高速に行えます。
(重複排除されたハッシュ値などのデータはAWSのDB上に格納されています)
inSyncはユーザ単位でのライセンスですので(もちろん容量制限はありますが)重複排除が直接コストに跳ね返るわけではないのですが、サーバ向けのPhoenixは重複排除後のデータ量に課金されますので、特に同じデータを複数拠点に持っているといったお客様でしたら有効に活用できるかと思います。
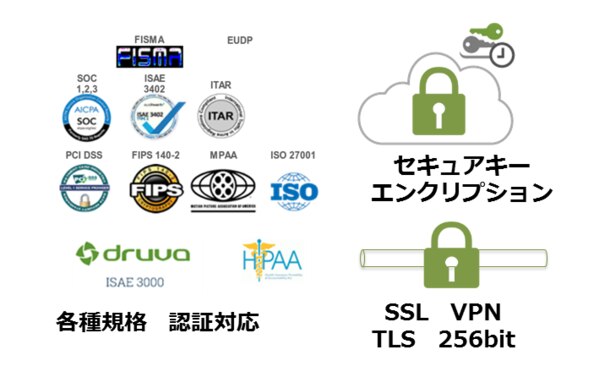
さらに各種の規格に準拠し、セキュアであることが挙げられます。
基盤自体はAWSもしくはAzure上に構築されていますのでそもそもその基盤上の各種規格に準拠します。
そして配置されたデータは暗号化されており、バックアップデータは顧客企業にのみアクセス可能です。
(Druvaは使用量しかわかりません)
また管理ユーザはロールベースで管理されます、当然転送されるデータも暗号化されています。

最後にバックアップ以外の利活用があります。
これはクラウド上にバックアップしてますので当然なのですが、オンプレでのバックアップと違い、データの遠隔地保管が必要ありません。
(広域災害を想定する場合はリージョンを考慮する必要がありますが)
また強力な検索機能やガバナンス機能も持ちますのでそういった用途に使用することも可能です。
今回はDruva製品の概略を説明させていただきましたが、いかがでしたでしょうか?
次回からDruva inSyncとPhoenixの具体的な機能や適用例をご紹介したいと思います。






