

ネットワーク業務とChatGPT②~RAG(検索拡張生成)のしくみ~
外部データベースの検索結果から回答生成する機能をRAG(Retrieval-Augmented Generation検索拡張生成)と呼びます。
簡単に言うと、検索結果のページから質問に関する情報を要約またはピックアップして回答を生成する機能です。
一般利用できるGPTは2021年のデータでの回答しかできませんが、このRAGの機能を使えば、インターネット検索や社内文書の検索結果から回答生成ができるため、回答の幅が増えます。
このことにより、ハルシネーション(生成AIがもっともらしい誤情報 "=事実とは異なる内容や、文脈と無関係な内容" を生成すること )の軽減には繋がります。(しかし、ゼロにすることはできません。)
多くの企業では、ChatGPTの社内導入の第1フェーズでは「社内向けGPTの導入」、第2フェーズでは「社内情報を使用したRAGの導入」という形で利活用を進めているところが多い状況です。ファインチューニング(LLMへの学習データの取込)は、大量データと数億かかる世界らしいので、まずは簡単に導入できるRAGから始めることが一般的です。(RAGはLLMにデータを学習させているわけではありません。そのあたりもこのブログで紹介していきます)
弊社でも、RAGの検証を行っています。
先ほど、RAGを使えば回答の幅が増えると書きました。しかし、RAGの基本システムを作っただけでは、理想的な回答が生成されることは難しいと感じています。
理想的な回答を得るには「仕組みの理解」「チューニング方法」「使い方」の知識が必要です。このブログでは回答精度を上げるためのヒントになる情報をお届けします。
目次[非表示]
- 1.■RAGの基本フロー
- 2.① 元データ準備
- 3.② Embedding(検索用データ生成)
- 4.③ Vector データベースへ保存
- 5.④ 質問
- 6.⑤ 検索
- 7.⑥ 質問文+ Context(検索結果)の送信
- 8.⑦ LLMで回答生成
- 9.⑧ 回答
- 10.まとめ
- 11.おまけ
■RAGの基本フロー
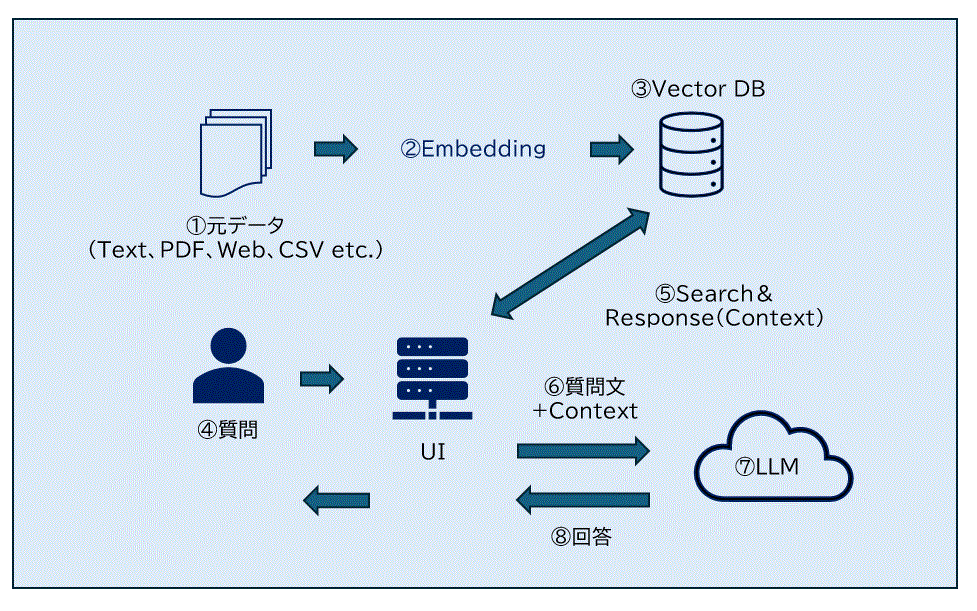
まずはRAGの基本フローは以下となります。
①元データの準備
②Embedding(検索用データ生成)
③Vectorデータベースへ保存
ここまでのプロセスが検索用データ準備になります。次からは回答生成のプロセスです。
④利用者の質問入力
⑤検索
⑥質問文+検索結果の内容をLLMに送信
⑦⑥の情報に基づきLLMが回答生成
⑧回答表示
次に各プロセスがどのような機能を持ち、どのようにチューニングを行えば回答精度が上がるのかを紹介していきます。
① 元データ準備
検索回答の情報元となるデータを用意します。元データはテキストやCSVに限らず、画像、PDF、Webなど様々な形式が利用可能ですが、実際にはCSVなどの構造化データ(テーブル形式のデータ)の方が回答精度がよい状況です。また、長すぎる文章は短く区切らないと、回答精度/応答速度が上がりません。このことをチャンク化と呼びます。チャンクのサイズは単純に文字数で区切ると文章的に意味不明な塊となる場合もあるので、元データや情報の質により適切なサイズが異なります。そのため、このチャンク化は精度を上げるための重要ポイントですが、ケースバイケースで対応する必要があります。
他にも、検索のためにタグ付けをした方がよいなど、「検索にヒットする」「回答生成の情報量が適切である」「処理速度とコスト」を意識した元データ作りが必要です。
つまり、RAGがどのような仕組みで動いているのかを理解していないと、適切な元データの作成が困難です。
② Embedding(検索用データ生成)
次にデータの検索技術の選択を行います。RAGではベクトル検索(セマンティック検索)を選択することが多いです。
代表的な検索技術として「キーワード検索」と「ベクトル検索」の2つがあり、「キーワード検索」は入力文字の完全一致、「ベクトル検索」は入力したキーワードが含まれていなくても、意味に近い情報を検索できます。
ベクトル検索を行うためには、単語や文章・画像などのデータを、それらの意味や関係性を捉える数値に変換する処理が必要です。このことをEmbeddingと呼びます。似たデータは似た数値が生成されることで、関連するものを判断できる情報と捉えてください。
この処理もEmbeddingに特化したAIが実行します。このAUモデル(計算式)が優れているほど、適切な検索結果が出ると言えます。
例えばGPTを利用する場合、OpenAIが作成したEmbeddingモデルであるText-embedding-ada-002を選択することが(簡単に実装できるので)一般的ですが、他にも性能が高いモデルがあるので、試してみる価値はあります。
参考)様々なEmbeddingモデル
https://huggingface.co/spaces/mteb/leaderboard
③ Vector データベースへ保存
Embeddingしたデータを保存するデータベースを選択します。前後のプロセスのコンポーネントと連携できるものを選択する必要があります。また、パフォーマンスや機能も考慮して選択すべきです。
先ほど、検索にはベクトル検索が多いとは書きましたが、情報の質によってはキーワード検索が向いてるものもあったり、ハイブリッド検索(ベクトル+キーワード)が回答精度が高いと言われています。データベースによっては、ハイブリッド検索はできるけど制約があったりするので、事前にRAGでどのような検索技術を使いたいのかを見定めておく方がよいと思います。
リレーショナルデータベース(RDB)のように歴史が古いわけでもなく、Vectorデータベースの種類は豊富なため、どれがいいのか、一発正解で見極めるのは難しいと思っています。やはりそのデータベースの特性についての情報が多い方が開発者側からすれば扱いやすいのでそういった目線から選択されることが多いと思います。
参考)Azureで使用できるVector データベース
https://learn.microsoft.com/en-us/semantic-kernel/memories/vector-db
④ 質問
質問の仕方でも回答が変わります。適切な回答をさせるにはプロンプトエンジニアリングが必要です。プロンプトエンジニアリングとは回答文にどのような要素があることが理想的なのかをLLMへ指示することです。こういうことは要素分解が得意な人であれば、簡単にできますが、不得意だと時間がかかります。
回答内容や形式のパターンが決まっているのであれば、⑥のプロセスで自動化することが可能なので、毎回パターンを入力する手間を省くことができます。
⑤ 検索
質問文の情報から検索が実行されますが、どの検索技術を使用したか、チャンク化したデータに適切な意味があるのか、により検索結果は異なります。
また、この検索結果を次のプロセスでLLMに送信するのですが、この時、チャンク化したデータだけなのか、全文にするのかは選択できます。しかし、LLMは入出力のトークン数には制限があります。このトークン数とはLLMが処理できる情報量(文字数)のことです。しかし、人間が考える文字数とLLMが認識する文字数には違いがあるのでこのような言い方になります。
また、トークン数によりコストが変化するため、そのあたりを配慮して決定する必要があります。
この入出力のトークン数に制約があるので、ハルシネーションを起こす原因の1つと感じています。(つまり、必要情報量が少ないので、嘘を生成してしまうことになります)
⑥ 質問文+ Context(検索結果)の送信
質問文と検索結果のデータ(Context)をLLMに送信し、回答生成を依頼します。どのような依頼文にするかはプログラミング次第なので、ここで回答形式についての指示を挿入することも可能です。
基本的には「質問文の回答を以下の(サーチ結果の)文章から生成して下さい」という依頼文をLLMに送信します。先ほども書いたようにこの文字数にはモデルによって使用できる量に制約があり、、また、多すぎても前後関係を上手く把握できなくなってしまうため、適切な回答が作れません。
まずは基本系でどのような回答をしてくるのかを検証し、どうすれば理想的な回答になるのかということを試行錯誤する必要があります。
⑦ LLMで回答生成
同じデータを渡してもLLMのモデルによって回答が違ってきます。また、一般公開されているGPTと社内向けに利用できるGPTではフィードバックが異なるため、同じ質問をしても同じような回答が返ってくるわけではありません。
また、GPTではGPT3.5と4というLLMモデルの選択肢がありますが、GPT4はコストが断然跳ね上がるので、そこも配慮して、どのモデルがいいのかを選択する必要があります。質問内容によっては3.5と4では違いがそう出ないものもあります。
⑧ 回答
これまで紹介してきたように回答の精度は、元データの性質、検索方法、LLMへのコンテキストの渡し方、Embeddingモデル、LLMモデル、プロンプトエンジニアリングなど様々な要素に依存します。
まとめ
紹介してきたように検索回答機能の実装は簡単ですが、望ましい回答をさせるには現状、様々な考察と検証と予算が必要です。元データがAIの回答生成に向いているような量と質であったら、こういった試行錯誤は不要ですが、なかなかそういう状況ではありません。
しかし、LLMの進化やノウハウが溜まっていけば、RAG用のデータ作成も生成AIによって自動化できるとは感じています。
また、GPT4では、すべてのカテゴリに長けているわけではなく、数十のカテゴリで機能するように作られています。(GPT5ではすべてのカテゴリで機能することを目指すとのこと。しかし、それがいつできるのかについては明言できないとのことでしたが、今年夏との噂もあります)
今はオープンソースではないのでどのような仕組みで作られているのかは噂でしかないのですが、数十のカテゴリで十分な性能を発揮させるために、各カテゴリの専門データ購入とカテゴリ毎の専用LLMがあるとかないとか。。。
何が言いたいかと言うと、理想的な回答をさせるには、そう簡単にはいかない、ということです。
しかし、いろいろ試行錯誤することで、今後何をすべきなのか、という改善点が見えてくるので、一歩先には進めますね!
このようにNOPでは先端技術を使って、業務改善ができないか、パートナー様に提供できるサービスを作れないかなど、いろいろな視点でAIを検証しています。
おまけ
一番上のRAGという絵は生成AIに作成したものです。RAG(検索拡張生成)という文字を青のイメージで写真ような絵で描いてくださいと依頼したら、こうなりました。
あたりさわりのない絵なので著作権にもひっかからないと思うので載せたのですが、意味不明の文字が一緒に書かれています。人が絶対使わない文字並びなので、生成AIが作ったのだろうなと予測がつきます。
今後、生成AIが作ったもの、フェイク情報などを見分ける技術が必要になってきます。今はこのように生成AIが作ったものってなんとなく分かるものも結構あります。しかし、詐欺メールも最初の頃は日本語の使い方が若干おかしいという状況から、今現在では本物そっくりに進化したようにこういったことも進化するのだろうな。。。と思っています。
今後、AI TRiSM(生成AIに対するリスク管理を指すガートナーの用語)が注目されるハズなので、このことに関してもいつかブログに掲載したいと思います。
では、次もお楽しみに!






